Baked-in Brilliance: Reranking Meets RL with mxbai-rerank-v2

Today, we're releasing our second generation of state-of-the-art reranking models—the mxbai‑rerank‑v2 family. Licensed under Apache 2.0, they’re as open as ever but now trained with reinforcement-learning for extra crispiness!
Read on to learn more about our approach, how it holds up against competitors, training process, and benchmarks. If you want to dive in immediately, you can access the models on Hugging Face:
- mixedbread-ai/mxbai-rerank-base-v2 (0.5B) – the best balance of size and performance.
- mixedbread-ai/mxbai-rerank-large-v2 (1.5B) – our strongest model for the most demanding tasks.
TLDR:
Our V2 Reranking Family comes with state-of-the-art performance across 100+ languages, extended context length, improved reasoning, and broad use-case support, outperforming Cohere, Voyage, and more.
Why Reranking MattersLink to section
Most search systems rely on a first-stage retriever (e.g., a keyword engine or vector search) to gather a set of candidate results. However, the top-ranked candidate isn't always the most relevant. Reranking addresses this by performing a second pass that "reorders" those candidates based on deeper semantic relevance.
Put simply, the reranker reads each candidate result alongside the query, scoring and sorting them so that truly relevant items rise to the top. This two-step approach can significantly enhance search quality—without having to revamp your existing search pipeline.

The reranking process from query to ranking
Why is this so powerful?Link to section
Many companies have invested in keyword-based search systems, and switching to a purely embedding or semantic/AI-based solution can be costly and complex (not with btw).
Reranking offers a sweet spot, where you keep your current setup and simply add a semantic layer. With a single line of code calling the reranker, you can tap into advanced language understanding.
As a result you get a better user experience. Relevant answers surface, irrelevant matches drop, and because our models are open-source licensed, you get this improvement on your terms, whether you self-host or use our API.
Introducing mxbai-rerank-v2: Setting New BenchmarksLink to section
We're excited to share our next-generation of crispy reranking models with you! Our new family includes two powerful options: mxbai-rerank-base-v2, a compact yet powerful 0.5B-parameter model with an excellent balance between size, speed, and performance, and mxbai-rerank-large-v2, our flagship 1.5B-parameter model with best-in-class accuracy and robust multilingual support for the best search accuracy.
Both handle 100+ languages, support long contexts up to 8k tokens (32k-compatible), and excel at complex query reasoning. They're also fast—delivering top-tier performance with minimal latency.
| Feature | V1 Models | V2 Models | Improvement |
|---|---|---|---|
| Architecture | Cross-encoder | RL-optimized Qwen-2.5 | More powerful base model |
| Parameters | Up to 435M | Up to 1.5B | Bigger, but better |
| Languages | English-focused | 100+ languages | Global coverage |
| Context Length | 512 tokens | 8K tokens (32K compatible) | 64x longer context |
| BEIR Score | 49.32 | 57.49 | +8 percentage points |
| Speed vs Quality | Good balance | 8x faster than similar models | Still Fast |
| Use Cases | Simple text support | Support for JSON, Code, MCP, more | Broader application support |
| License | Apache 2.0 | Apache 2.0 | Open Source ✅ |
Fast & State of the Art: Performance AnalysisLink to section
We tested the mxbai-rerank-v2 models on English, Chinese, multilingual, tool retrieval, and code-search benchmarks, comparing them to other open- and closed-source models.
The results are impressive outperforming open and closed source competitors such as Cohere or Voyage by a good margin.
English (BEIR Average)
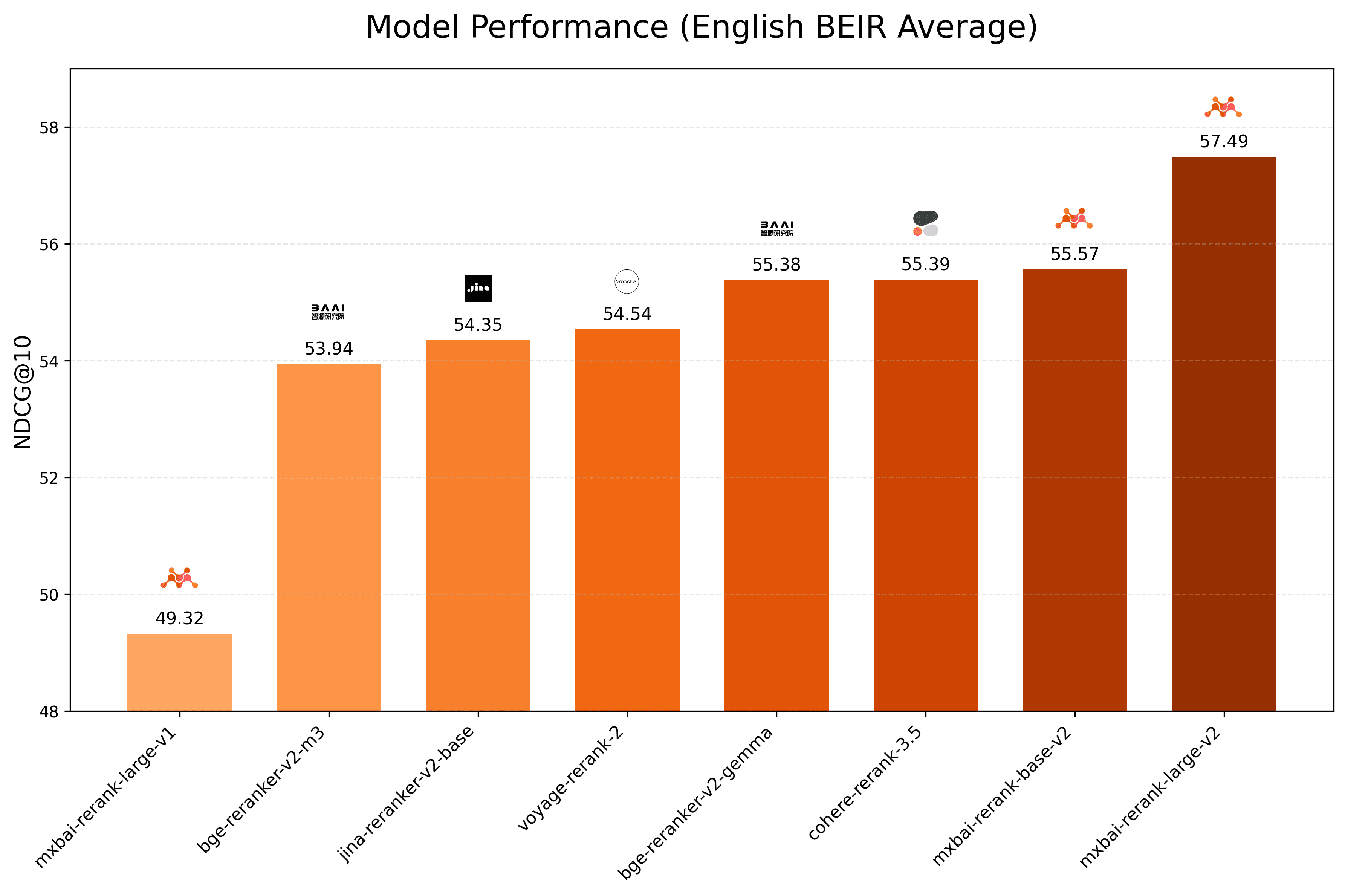
BEIR Benchmark Performance.
| Model | NDCG@10 |
|---|---|
| mixedbread-ai/mxbai-rerank-large-v2 (1.5B) | 57.49 |
| mixedbread-ai/mxbai-rerank-base-v2 (0.5B) | 55.57 |
| cohere-rerank-3.5 | 55.39 |
| BAAI/bge-reranker-v2-gemma (2.5B) | 55.38 |
| voyage-rerank-2 | 54.54 |
| jinaai/jina-reranker-v2-base-multilingual | 54.35 |
| BAAI/bge-reranker-v2-m3 (568M) | 53.94 |
| mixedbread-ai/mxbai-rerank-large-v1 (435M) | 49.32 |
BEIR is the industry-standard benchmark for evaluating English-language information retrieval models. Mixedbread’s rerank-v2 leads the BEIR leaderboard, outperforming all competing models and approaching the effectiveness of state-of-the-art embedding models, while using BM25 as the first stage retriever.
Our models significantly improve search quality by re-ranking candidate documents to better align with user queries. The large variant (1.5B parameters) achieves a 57.49 BEIR score, the highest in the benchmark, while even our base variant (0.5B) surpasses much larger models with an impressive 55.57 score.
This represents a major improvement over our previous generation, with v2 models showing over 8-point gains compared to v1. These improvements make our rerankers highly valuable for production environments where retrieval quality is critical—without the extreme resource demands of larger models. Organizations can now deploy state-of-the-art search capabilities efficiently, ensuring high accuracy and optimal performance.
For all benchmarks we used keyword-based (BM25) retrieval as the first stage retriever. For more details, please check out the spreadsheet.
Latency ComparisonLink to section
To understand how quickly each model processes queries in real-world settings, we measured average latency per query (seconds) on the NFCorpus dataset using an A100 (80GB) GPU:
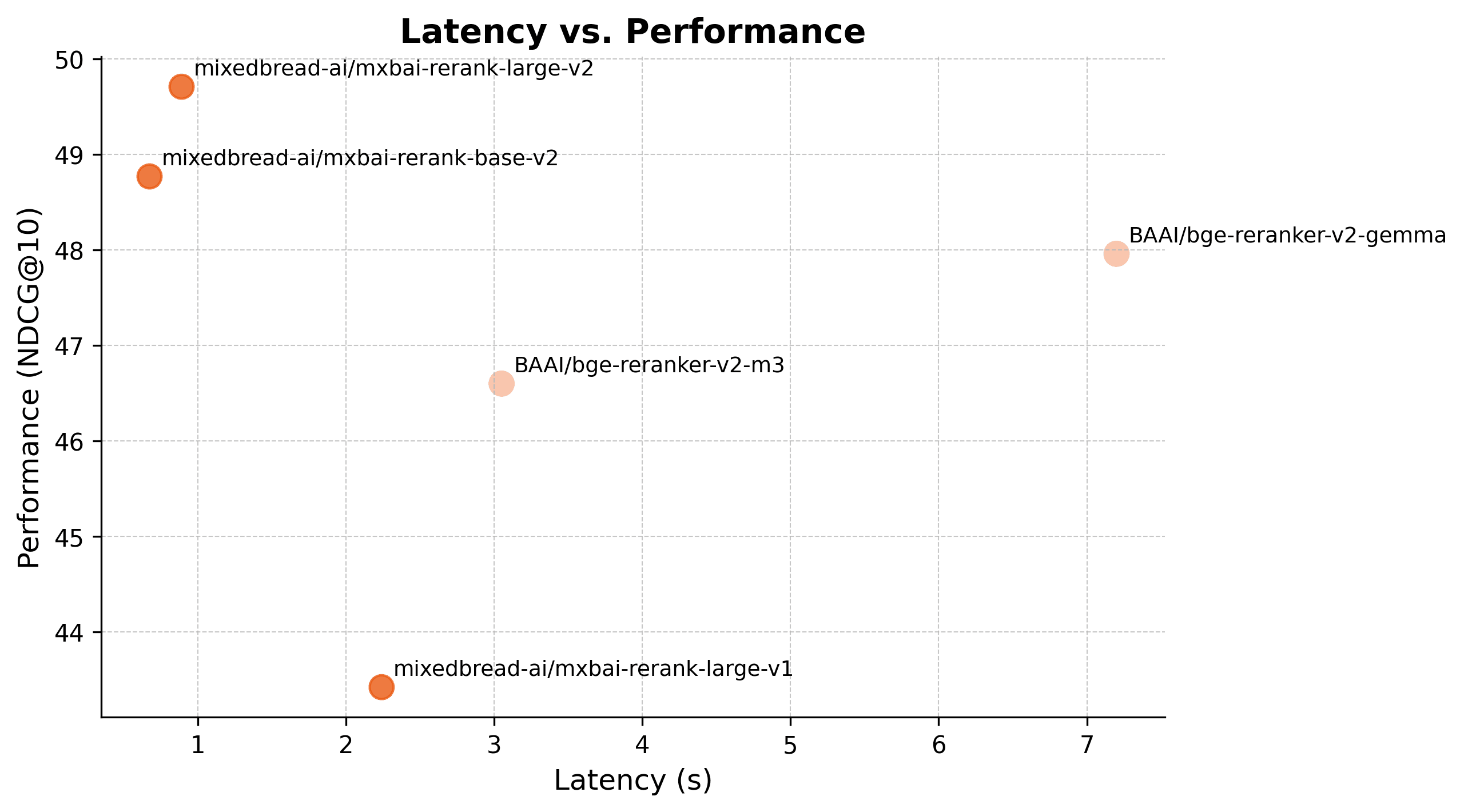
| Model | Latency (s) |
|---|---|
| mixedbread-ai/mxbai-rerank-xsmall-v1 | 0.32 |
| mixedbread-ai/mxbai-rerank-base-v2 | 0.67 |
| mixedbread-ai/mxbai-rerank-base-v1 | 0.76 |
| mixedbread-ai/mxbai-rerank-large-v2 | 0.89 |
| mixedbread-ai/mxbai-rerank-large-v1 | 2.24 |
| BAAI/bge-reranker-v2-m3 | 3.05 |
| BAAI/bge-reranker-v2-gemma | 7.20 |
Our 1.5B model is 8x faster than bge-reranker-v2-gemma while delivering higher accuracy. This speed advantage means you can process more queries per second without sacrificing quality, making our models ideal for high-volume production environments where both performance and cost-efficiency matter.
How We Trained the ModelsLink to section
Building on insights from DeepSeek R-1 and starting with Qwen-2.5, we used a three-step reinforcement-learning process:

The training process used for mxbai-rerank-v2
-
GRPO (Guided Reinforcement Prompt Optimization)
We taught the model to output 1 for relevant documents and 0 for irrelevant ones. GRPO ensures format consistency and gives a strong performance boost from the start. -
Contrastive Learning
Next, we gave the model a fine-grained understanding of query-document relationships, much like embedding models learn deeper semantic similarity. -
Preference Learning
Finally, we tuned the model to rank the most relevant documents highest—mirroring how real users judge search results.
This layered approach yields a richer query understanding, whether you're reordering text results, code snippets, or product listings.
A detailed technical paper is on the way, with an in-depth look at our methodology, architecture, and additional benchmarks.
Try It OutLink to section
If you’d like to see how mxbai‑rerank‑v2 performs in your own search setup, there are two ways to use the models, either via Python or using the Mixedbread API. Here's how you get started:
pip install -U mxbai-rerankBelow is a basic Python snippet that sends a query and multiple candidate passages to the mxbai‑rerank‑v2 model. The model scores each passage, helping you rank the most relevant content at the top:
from mxbai_rerank import MxbaiRerankV2
# Load the model, here we use our base sized model
model = MxbaiRerankV2("mixedbread-ai/mxbai-rerank-base-v2")
# Example query and documents
query = "Who wrote To Kill a Mockingbird?"
documents = [
"To Kill a Mockingbird is a novel by Harper Lee published in 1960. It was immediately successful, winning the Pulitzer Prize, and has become a classic of modern American literature.",
"The novel Moby-Dick was written by Herman Melville and first published in 1851. It is considered a masterpiece of American literature and deals with complex themes of obsession, revenge, and the conflict between good and evil.",
"Harper Lee, an American novelist widely known for her novel To Kill a Mockingbird, was born in 1926 in Monroeville, Alabama. She received the Pulitzer Prize for Fiction in 1961.",
"Jane Austen was an English novelist known primarily for her six major novels, which interpret, critique and comment upon the British landed gentry at the end of the 18th century.",
"The Harry Potter series, which consists of seven fantasy novels written by British author J.K. Rowling, is among the most popular and critically acclaimed books of the modern era.",
"The Great Gatsby, a novel written by American author F. Scott Fitzgerald, was published in 1925. The story is set in the Jazz Age and follows the life of millionaire Jay Gatsby and his pursuit of Daisy Buchanan."
]
# Calculate the scores
results = model.rank(query, documents)Once you have the scores, you can reorder your documents based on their ranking. This approach quickly upgrades the “second pass” in your search pipeline, making results more relevant without overhauling your entire search infrastructure.
Reranking Beyond Document RetrievalLink to section
When most people think of reranking, they picture standard document search. However, the latest v2 models demonstrate that reranking can be applied to a much broader set of tasks. Here are a few key examples:
-
Code, SQL & Technical Documentation
By understanding programming syntax, SQL, and documentation structures, our model surface the most relevant sections within repositories, developer wikis, or technical manuals. This approach balances semantic intent with the specific language of code, making it highly effective for technical searches. -
LLM Tool Selection & Function Calling
When you have thousands of functions, MCP definitions, or API endpoints, choosing the right one for a given query can be challenging. The model assists by aligning the query’s intent with the most appropriate tool or function—particularly useful for AI assistants working with the MCP protocol or any other mechanism that requires precise function calls. -
E-Commerce Product Discovery
In large product catalogs, simply matching keywords often falls short of user expectations. Instead, the model examines product attributes, descriptions, and user intent to highlight the most relevant options. It also factors in details such as specifications and reviews, offering a more nuanced ranking than generic keyword-based methods. -
Structured Data & JSON
Traditional rerankers often struggle with structured formats, but our approach is designed to interpret relationships between fields and values. This makes it straightforward to locate relevant entries in complex databases or JSON documents—another step beyond plain-text ranking. -
Mixed Content Types
Often, data comes in various formats: text, metadata, technical specs, or category tags. By combining these different signals, the model produces a unified relevance judgment that reflects the bigger picture, rather than focusing on a single type of content.
This versatility means you can rely on a single open-source model for use cases ranging from customer-facing searches to internal knowledge management and developer tools—without needing separate rerankers for each part of your tech stack.
Give Us FeedbackLink to section
We'd love to hear your thoughts on mxbai-rerank-v2! Whether you're reranking web pages, SQL queries, code snippets, or product listings, let us know how it performs and how we can improve.
Join our Discord to share your experience, ask questions, and connect with other developers. Follow us on X and LinkedIn for releases and updates!
Happy baking!
Reach out if you're looking for an end-to-end solution or direct support. We’d love to help you bake the perfect search stack.
CitationLink to section
@online{v2rerank2025mxbai,
title={Baked-in Brilliance: Reranking Meets RL with mxbai-rerank-v2},
author={Sean Lee and Rui Huang and Aamir Shakir and Julius Lipp},
year={2025},
url={https://www.mixedbread.com/blog/mxbai-rerank-v2},
}